本人没咋学编译原理,能力有限,写的不好轻点喷,大佬路过的话,那你就路过就好
东大编译原理实验课原题,22年
1. 基本题:简单的扫描器设计
【问题描述】
熟悉并实现一个简单的扫描器,设计扫描器的自动机;设计翻译、生成Token的算法;编写代码并上机调试运行通过。
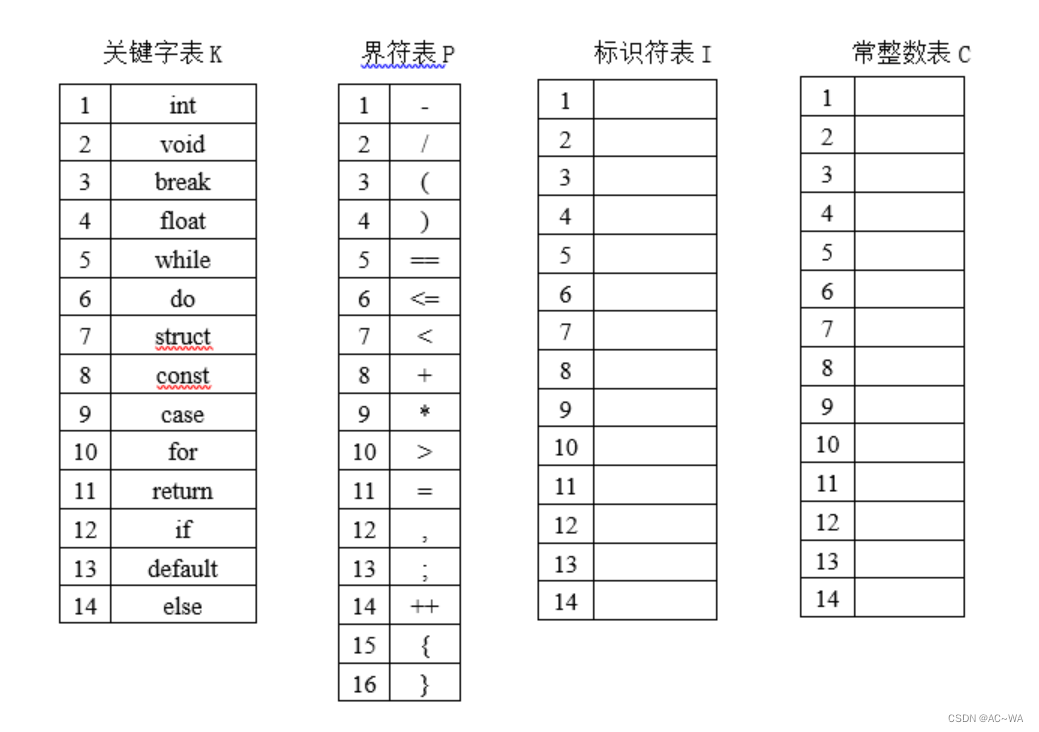
要求扫描器可识别的单词包括:关键字、界符、标识符和常整形数。
其中关键字表、界符表、标识符表、常整数表如下:(表中没有的关键字、界符等可以接着编号继续扩展)
【输入形式】源程序文件
【输出形式】
相应单词的Token序列;
标识符表,常数表。
【样例输入】
x10=x+y1*120+10;
【样例输出】
注意每行输出最后没有多余空格,最后一行输出后不换行。
Token :(I 1)(P 11)(I 2)(P 8)(I 3)(P 9)(C 1)(P 8)(C 2)(P 13)
I :x10 x y1
C :120 10
大体思路
我这里用了unordered_map来对应存<string,int> ,但是unordered_map他存进去后的顺序是胡乱的,不利于输出,我就直接存到vector里输出了,建议可以用pair<string,int> 方便点。
然后就是把想到的一些关键字,界符什么的初始化一下。
文件输入输出就上网一查,很多用法都有,我这里用了一种比较方便的。
从文本里一行一行的读入数据,存到一个string变量里,然后就对这个string从头到尾跑一遍,分三种情况,第一种是界符,如果当前字符是界符,那就再看看下一个字母是不是+,=这样的能够满足==,++,–这样的符号。第二种情况就是第一个字母为数字,这种呢就要么是标识符,要么就是整数了,分情况讨论就行。第三种就是第一个字母是字母,那这种就是要么关键字,要么标识符了
过验收的代码(文件输入输出)
里边的小注释是我用来debug的,一些没用到的变量是给第二题的,第二题题目看着怪怪的,不想写了,也懒得改了
#include<iostream>
#include<unordered_map>
#include<cstdio>
#include<cstring>
#include<cstdlib>
#include<vector>
#include<fstream>
using namespace std;
unordered_map<string,int> keyK;//这个无序是胡乱排序,也不按照自己输入的顺序,后来知道了懒得改了,直接套个vector输出吧
unordered_map<string,int> keyP;
unordered_map<string,int> keyI;
unordered_map<string,int> keyC1;
unordered_map<string,int> keyC2;
unordered_map<string,int> keyCT;
unordered_map<string,int> keyST;
vector<string> I;
vector<string> C1;
vector<string> C2;
vector<string> CT;
vector<string> ST;
int idxI=1,idxC1=1,idxC2=1,idxCT=1,idxST=1;
int kind(char ch)
{
if ((ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z')) return 1;
if (ch>='0'&&ch<='9') return 2;
if (ch=='-'||ch=='/'||ch=='('||ch==')'||ch=='='||ch=='<'||ch=='>'||ch=='+'||ch=='*'||ch==','||ch==';'||ch=='{'||ch=='}'||ch=='"') return 3;
return 0;
}
void init()
{
keyK["int"]=1,keyK["void"]=2,keyK["break"]=3,keyK["float"]=4,keyK["while"]=5;
keyK["do"]=6,keyK["struct"]=7,keyK["const"]=8,keyK["case"]=9,keyK["for"]=10;
keyK["return"]=11,keyK["if"]=12,keyK["default"]=13,keyK["else"]=14;
keyK["long"]=15,keyK["short"]=16,keyK["double"]=17,keyK["char"]=18;
keyK["unsigned"]=19,keyK["signed"]=20,keyK["union"]=21,keyK["goto"]=22;
keyK["switch"]=23,keyK["continue"]=24,keyK["typedef"]=25,keyK["cout"]=26;
keyK["cin"]=27,keyK["main"]=28,keyK["printf"]=29,keyK["scanf"]=30;
keyP["-"]=1,keyP["/"]=2,keyP["("]=3,keyP[")"]=4,keyP["=="]=5,keyP["<="]=6;
keyP["<"]=7,keyP["+"]=8,keyP["*"]=9,keyP[">"]=10,keyP["="]=11,keyP[","]=12;
keyP[";"]=13,keyP["++"]=14,keyP["{"]=15,keyP["}"]=16,keyP["["]=17,keyP["]"]=18;
}
int main()
{
init();
//for (auto i:keyK) cout<<i.first<<" "<<i.second<<"\n";
//for (auto i:keyP) cout<<i.first<<" "<<i.second<<"\n";
ifstream infile;
infile.open("data2.txt",ios::in);
if (!infile.is_open())
{
printf("Not found file!\n");
return 0;
}
cout<<"Token :";
string input;
while(getline(infile,input))
{
for (int i=0;i<(int)input.size();i++)
{
string tmp;
//cout<<i<<" "<<input[i]<<" "<<kind(input[i])<<"\n";
if (kind(input[i])==3) {
//cout<<"i=P"<<i<<" ";
string tt;
if (input[i+1]=='='||input[i+1]=='+') {
tt+=input[i];
tt+=input[i+1];
cout<<"(P "<<keyP[tt]<<")";
i++;
}
else {
tt+=input[i];
cout<<"(P "<<keyP[tt]<<")";
}
}
else if (kind(input[i])==2) {
//cout<<"i=C"<<i<<" ";
bool flag=false;
while (kind(input[i])!=3) {
if (kind(input[i])==1) flag=true;
tmp+=input[i];
i++;
}
i--;
if (keyI.find(tmp)!=keyI.end()) {
cout<<"(I "<<keyI[tmp]<<")";
}
else if (keyC1.find(tmp)!=keyC1.end()) {
cout<<"(C1 "<<keyC1[tmp]<<")";
}
else {
if (flag) {
keyI[tmp]=idxI;
I.push_back(tmp);
cout<<"(I "<<idxI<<")";
idxI++;
}
else {
keyC1[tmp]=idxC1;
C1.push_back(tmp);
cout<<"(C1 "<<idxC1<<")";
idxC1++;
}
}
}
else if (kind(input[i])==1) {
//cout<<"i=K"<<i<<" ";
bool Find=false;
while (kind(input[i])!=3) {
tmp+=input[i];
if (keyK.find(tmp)!=keyK.end()) {
Find=true;
cout<<"(K "<<keyK[tmp]<<")";
break;
}
i++;
}
if (Find) continue;
i--;
if (keyK.find(tmp)!=keyK.end()) {
cout<<"(K "<<keyK[tmp]<<")";
}
else if (keyI.find(tmp)!=keyI.end()) {
cout<<"(I "<<keyI[tmp]<<")";
}
else {
keyI[tmp]=idxI;
I.push_back(tmp);
cout<<"(I "<<idxI<<")";
idxI++;
}
}
//cout<<"2 "<<i<<" "<<input[i]<<" "<<kind(input[i])<<"\n";
}
}
cout<<"\nI :";
bool flag=false;
for (auto i:I) {
if (!flag) flag=true;
else cout<<" ";
cout<<i;
}
cout<<"\n";
cout<<"C1 :";
flag=false;
for (auto i:C1) {
if (!flag) flag=true;
else cout<<" ";
cout<<i;
}
return 0;
}
都能过测试点的代码,虽然说我感觉输出有点奇怪,但能满分就行,懒得管了
#include<iostream>
#include<unordered_map>
#include<cstdio>
#include<cstring>
#include<cstdlib>
#include<vector>
#include<fstream>
using namespace std;
unordered_map<string,int> keyK;//这个无序是胡乱排序,也不按照自己输入的顺序,后来知道了懒得改了,直接套个vector输出吧
unordered_map<string,int> keyP;
unordered_map<string,int> keyI;
unordered_map<string,int> keyC;
vector<string> I;
vector<string> C;
int idxI=1,idxC=1;
int kind(char ch)
{
if ((ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z')) return 1;
if (ch>='0'&&ch<='9') return 2;
if (ch=='-'||ch=='/'||ch=='('||ch==')'||ch=='='||ch=='<'||ch=='>'||ch=='+'||ch=='*'||ch==','||ch==';'||ch=='{'||ch=='}'||ch=='"') return 3;
return 0;
}
void init()
{
keyK["int"]=1,keyK["void"]=2,keyK["break"]=3,keyK["float"]=4,keyK["while"]=5;
keyK["do"]=6,keyK["struct"]=7,keyK["const"]=8,keyK["case"]=9,keyK["for"]=10;
keyK["return"]=11,keyK["if"]=12,keyK["default"]=13,keyK["else"]=14;
keyK["long"]=15,keyK["short"]=16,keyK["double"]=17,keyK["char"]=18;
keyK["unsigned"]=19,keyK["signed"]=20,keyK["union"]=21,keyK["goto"]=22;
keyK["switch"]=23,keyK["continue"]=24,keyK["typedef"]=25,keyK["cout"]=26;
keyK["cin"]=27,keyK["main"]=28,keyK["printf"]=29,keyK["scanf"]=30;
keyP["-"]=1,keyP["/"]=2,keyP["("]=3,keyP[")"]=4,keyP["=="]=5,keyP["<="]=6;
keyP["<"]=7,keyP["+"]=8,keyP["*"]=9,keyP[">"]=10,keyP["="]=11,keyP[","]=12;
keyP[";"]=13,keyP["++"]=14,keyP["{"]=15,keyP["}"]=16,keyP["["]=17,keyP["]"]=18;
}
int main()
{
init();
//for (auto i:keyK) cout<<i.first<<" "<<i.second<<"\n";
//for (auto i:keyP) cout<<i.first<<" "<<i.second<<"\n";
/*
ifstream infile;
infile.open("data2.txt",ios::in);
if (!infile.is_open())
{
printf("Not found file!\n");
return 0;
}*/ //这里是文件输入输出,你就在cpp文件位置旁边建一个data2.txt文件就行
cout<<"Token :";
string input;
while(getline(cin,input))
{
for (int i=0;i<(int)input.size();i++)
{
string tmp;
//cout<<i<<" "<<input[i]<<" "<<kind(input[i])<<"\n";
if (kind(input[i])==3) {
//cout<<"i=P"<<i<<" ";
string tt;
if (input[i+1]=='='||input[i+1]=='+') {
tt+=input[i];
tt+=input[i+1];
cout<<"(P "<<keyP[tt]<<")";
i++;
}
else {
tt+=input[i];
cout<<"(P "<<keyP[tt]<<")";
}
}
else if (kind(input[i])==2) {
//cout<<"i=C"<<i<<" ";
bool flag=false;
while (kind(input[i])!=3) {
if (kind(input[i])==1) flag=true;
tmp+=input[i];
i++;
}
i--;
if (keyI.find(tmp)!=keyI.end()) {
cout<<"(I "<<keyI[tmp]<<")";
}
else if (keyC.find(tmp)!=keyC.end()) {
cout<<"(C "<<keyC[tmp]<<")";
}
else {
if (flag) {
keyI[tmp]=idxI;
I.push_back(tmp);
cout<<"(I "<<idxI<<")";
idxI++;
}
else {
keyC[tmp]=idxC;
C.push_back(tmp);
cout<<"(C "<<idxC<<")";
idxC++;
}
}
}
else if (kind(input[i])==1) {
//cout<<"i=K"<<i<<" ";
bool Find=false;
while (kind(input[i])!=3) {
tmp+=input[i];
if (keyK.find(tmp)!=keyK.end()) {
Find=true;
cout<<"(K "<<keyK[tmp]<<")";
break;
}
i++;
}
if (Find) continue;
i--;
if (keyK.find(tmp)!=keyK.end()) {
cout<<"(K "<<keyK[tmp]<<")";
}
else if (keyI.find(tmp)!=keyI.end()) {
cout<<"(I "<<keyI[tmp]<<")";
}
else {
keyI[tmp]=idxI;
I.push_back(tmp);
cout<<"(I "<<idxI<<")";
idxI++;
}
}
//cout<<"2 "<<i<<" "<<input[i]<<" "<<kind(input[i])<<"\n";
}
}
cout<<"\nI :";
bool flag=false;
for (auto i:I) {
if (!flag) flag=true;
else cout<<" ";
cout<<i;
}
cout<<"\n";
cout<<"C :";
flag=false;
for (auto i:C) {
if (!flag) flag=true;
else cout<<" ";
cout<<i;
}
return 0;
}
2. 扩展题:扫描器类的设计
【问题描述】
熟悉并实现一个简单的扫描器,设计扫描器的自动机;设计翻译、生成Token的算法;编写代码并上机调试运行通过。
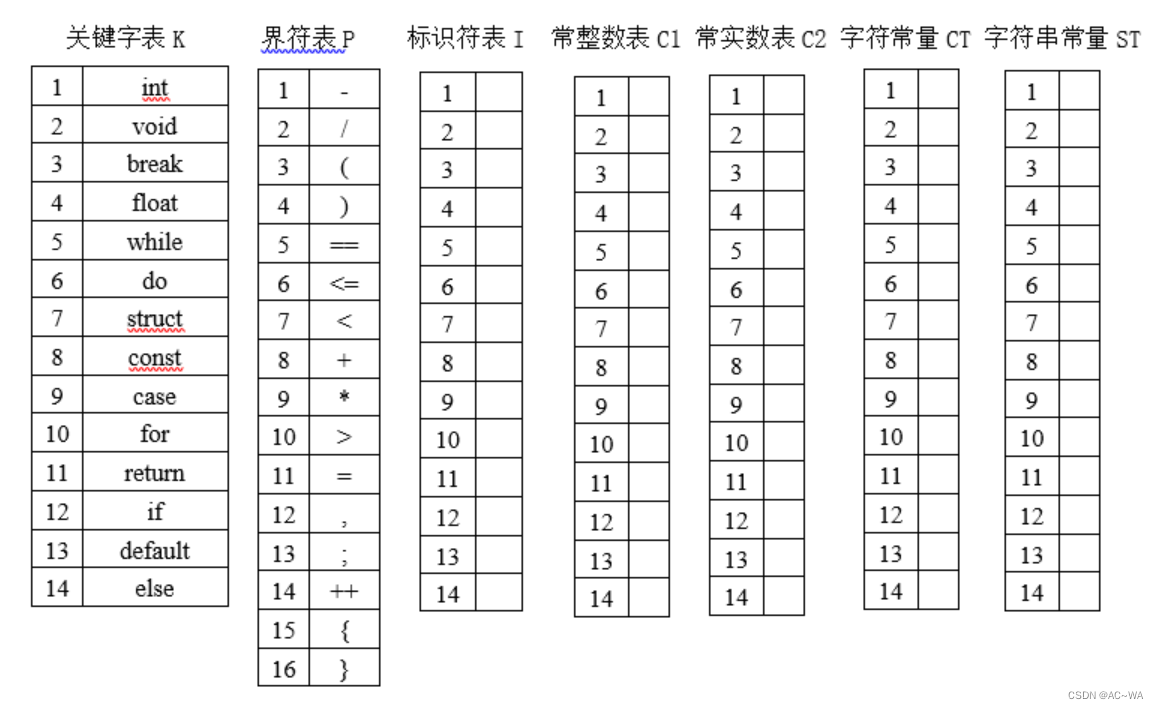
扫描器可识别的单词包括:关键字、界符、标识符和常数(常数包括如:123 123.567 0.567 12.34e+23 …);
要求常整数输出按十进制输出(测试数据中只有16进制与10进制整数),浮点数考虑到精度问题按输入格式输出(测试数据只有10进制浮点数)。同时使用科学计数法的数字都是浮点数。为降低难度,样例3给出一种边界情况供大家调试。
在面对诸如"a+++++b"以及"a+++b"这种丧心病狂的输入时,界符匹配按照从左向右贪心匹配最长界符的策略进行匹配。
判断字符常量及字符串常量单词,将字符和字符串常量分别保存进单独的常量表CT、ST。例如’a’、”OK”;同时字符串与字符常量均不考虑转义字符("“和带”"的都不考虑)。
可以识别简单的词法错误主要形式为’sdddd’、1.sdasf等,尚未定义的单词等。
其中关键字表、界符表、标识符表、常整数表、常实数表、字符表、字符串表如下:(表中除关键词与界符表的表都可以接着编号继续扩展)
【输入形式】一行带空格的输入。其中关于数字,对于整型保证仅需考虑10进制与16进制数据,对于浮点型保证仅需考虑10进制数据。
【输出形式】
相应单词的Token序列;
标识符表,整数表,实数表,字符表,字符串表
如果错误则输出"ERROR"。
样例输入】
样例1输入:
120+10.3*12.3e-1;
样例2输入:
a="xyz";
样例3输入:
int a=12.1; float b=15e2, c=0x15e2;
样例4输入:
int a='label';
【样例输出】
样例1输出:
Token :(C1 1)(P 8)(C2 1)(P 9)(C2 2)(P 13)
I :
C1 :120
C2 :10.3 12.3e-1
CT :
ST :
样例2输出:
Token :(I 1)(P 11)(ST 1)(P 13)
I :a
C1 :
C2 :
CT :
ST :xyz
样例3输出:
Token :(K 1)(I 1)(P 11)(C2 1)(P 13)(K 4)(I 2)(P 11)(C2 2)(P 12)(I 3)(P 11)(C1 1)(P 13)
I :a b c
C1 :5602
C2 :12.1 15e2
CT :
ST :
样例4输出:
ERROR